微服务设计模式-业务逻辑设计
使用领域驱动模型的聚合模式,可以很好地构架一个服务的业务逻辑为一个聚合的集合。一个聚合是指可以划分为一个单元的一堆对象。 聚合在微服务架构中如此重要的原因有以下两点:
- 聚合可以避免跨越服务边界的对象引用。因为内部聚合引用是主键值,而不是对象引用。
- 一个事务只能发生在一个单聚合中,聚合贴合了微服务事务模型的限制。
结果就是,可以在一个单服务内确保ACID事务。
业务逻辑组织模式
如下是一个典型的服务架构,业务逻辑是一个六边形架构的核心。围绕业务服务的有入站(inbound)和出站(outbound)适配器。 一个入站适配器处理客户端的请求并调用业务逻辑。出站适配器用于业务逻辑调用其他的服务和应用。
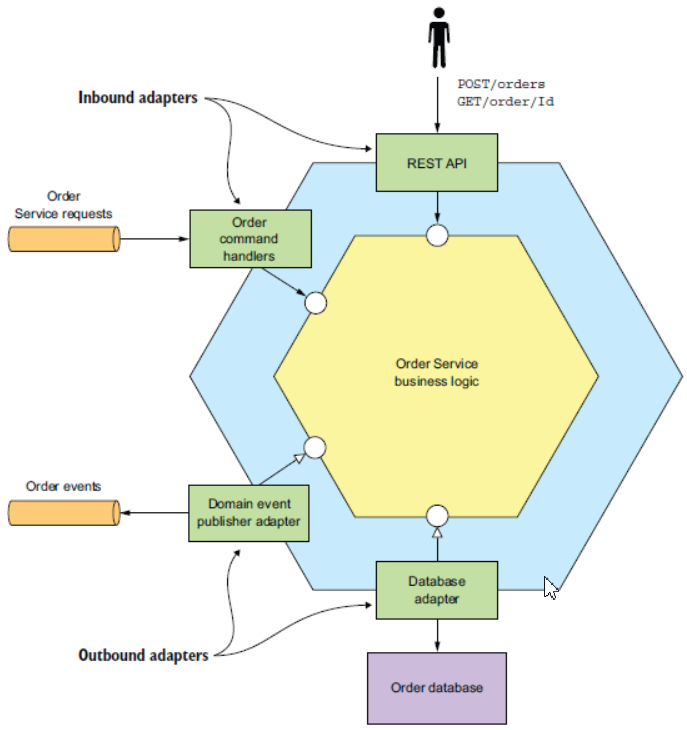
服务由业务逻辑和如下适配器组成:
- Rest Api Adapter-是入站适配器,实现REST API并调用业务逻辑。
- OrderCommandHandlers-是入站适配器,从一个消息通道消费消息并调用业务逻辑。
- DataBase Adapter-是出站适配器,被业务逻辑调用,用来访问数据库。
- Domain Event Publishing Adapter-出站适配器,向一个消息中间件发布事件。
事务脚本模式
尽管面向对象的方式有诸多好处,但是一些简单地业务逻辑,面向过程的代码更好用。事务脚本模式就是这样一种 常见的模式,它将类的行为和状态分开,使用DAO对数据库进行访问。如下图,你会觉得很熟悉:
![]()
领域模型模式
如果业务逻辑变得很复杂,那么面向过程的代码将会是噩梦。这就需要使用面向对象的模型。 领域模型模式:是一种对象模型,会将业务逻辑组织为包含行为和状态的若干个类,这些类可能拥有行为和状态两者。 如下图,DeliveryInfomation只包含了状态,OrderService和OrderRepository只包含行为,但是更多的类,如Order两者都有。

在领域模型模式中,service的方法通常很简单。因为一个service方法几乎总是到持久化的领域对象中,包含了大部分的业务逻辑。 而且,如Order包含了状态和行为,那么,它的状态是私有的,只能通过它的方法直接访问。
面向对象的设计有很多好处。
- 它由一些列小的类组成,每个类的责任单一,所以便于理解和维护。
- 每个类都是映射现实世界中的事务,在设计上很容易理解。
- 面向对象设计容易测试,每个类能够并且应该独立地进行测试。
- 面向对象设计容易扩展,有很多有名的设计模式(策略模式,模板模式等)可以应用,不需要修改代码就能扩充一个组件。
但是领域模型模式在微服务中还是会有很多问题。为了解决这些问题,你需要使用DDD改进领域模型模式。
领域驱动设计
使用DDD后,每个服务有他自己的领域模型,避免了整个应用的单一领域模型出现。子领域和边界上下文是两个重要的DDD模式。 DDD有很多模式是领域模型的主要组成部分,这些模式已经被开发者广泛采用:
- Entity-具有持久标识的对象。两个具有相同值的实体,依然是不同的对象。如使用JPA @Entity注解的类就是一个DDD实体。
- value object-拥有一系列值的对象,两个属性值相同的对象可以互换。一个例子是Money类,由货币和金额组成。
- factory-有时候构建一个对象的逻辑过于复杂,构造方法无法完成,就会使用工厂模式,它还可以影藏实例化的具体类, 工厂模式通常可以实现为静态方法。
- Repository-提供了实例化实体和封装了访问数据库逻辑的对象。
- Service-实现业务逻辑。
使用DDD聚合模式设计一个领域模型。
在传统的面向对象设计中,一个领域模型是一系列类和他们之间的关系。如下图:
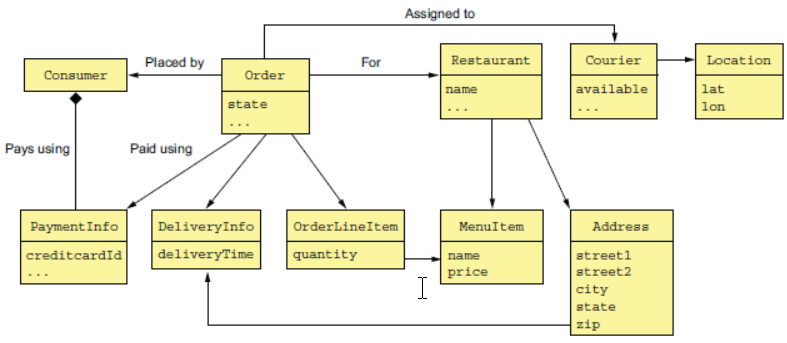
这个例子对应了一些业务对象,但是每个业务对象的明确的边界并没有指明。对于微服务来说,缺少了边界,会引起概念混乱,这一点很关键。
聚合拥有明确的边界
聚合——在某个边界内可以被当成一个单元的领域对象集合。包括一个根实体和其他若干实体和值对象。如Order,Consumer,Restaurant等, 都是聚合。下图展示了Order聚合的结构。

聚合将一个领域模型分解为多个易于理解的独立的块。明确了增,删,改等操作影响的范围。这些操作作用于整个聚合而不是聚合的一部分。 一个聚合经常从数据库中整体加载出来。避免了延迟加载的后遗症,对应的删除,会从数据库中删除聚合的所有对象。
聚合拥有一致性边界
对比部分更新聚合同时解决一致性问题,更新整个聚合更加方便。更新操作在聚合的根实体中,业务对象的不变性会得到了加强。如,客户端 必须调用订单聚合根实体的某个方法,而不是直接更改商品的数量。并且并发可以通过锁定聚合的根实体的使用来实现,如一个数据库层级的 版本号。
区分聚合是关键
在DDD中,区分聚合是设计领域模型的关键因素之一,以及聚合的边界和聚合的根实体。聚合内部结构是次要的。
聚合的规则
遵从如下规则,保证了聚合是一个独立的单元,增强了聚合的不变性:
-
仅引用聚合根。 聚合外部类只能引用聚合根实体,客户端只能调用聚合根中的方法更新一个聚合。该规则加强了聚合的不变性。
- 聚合内部必须使用聚合的主键。
聚合内部使用Id引用而不是对象引用。如Order中通过consumerId关联一个Consumer,而不是Consumer对象。这里,和传统的对象模型完全不同。
这样有几个明显的好处:
- 用id关联让聚合称为松耦合结构。
- 如果一个聚合是另一个服务的一部分,没有跨服务之间的对象引用。
- 简化了持久层,可以很容易存储在Nosql中,如MongoDB。
- 消除了懒加载和相关问题。
- 通过分片聚合扩展数据库很方便。
- 一个事务创建或者更新一个聚合。 传统的RDBMS,一个事务可能会更新多个聚合,而微服务中,一个事务只在一个服务中。这条规则也正好弥补了多数NoSql数据库事务模型的不足。 这条规则也给创建和更新多个聚合带来了困难,那就是分布式事务需要解决的问题了,如sagas。如下图:

上图中,每个事务都只更新一个聚合,当然,如果使用强事务的RDBMS,也可以在一个事务在一个服务中更新多个聚合。如果使用NoSql,那么 你没的选择。这样看来,聚合的边界也不是一成不变的,但是划分还是要非常慎重。
聚合的粒度
划分聚合的粒度是你需要作出的关键决定,一方面,聚合划分的足够小,可以增加应用的并发请求数,提高可扩展性。同时,更小的粒度减小 了两个用户同时操作一个聚会的几率,提高了用户体验。另一方面,考虑到事务,聚合需要足够大,保证更新的原子性。
领域事件发布
在DDD中,领域事件是聚合发生的一些事情。一个领域事件通常代表一个状态的改变。如订单创建,订单取消等。
领域事件发布的起因
发布领域事件通常情况如下:
- 跨服务保持数据的一致性,如分布式事务。
- 通知一个服务,它持有的一份数据拷贝的数据源有改变。这通常被称为CQRS(Command Query Responsibility Segregation),命令查询 责任分离。
- 通过一个webhook或者消息中间件通知另一个应用触发业务过程的下一步。
- 通知同一个应用中的其他组件,如发送一个websocke消息给浏览器或者更新一个如ES的文本数据库。
领域事件是什么
一个领域事件是一个过去式动词修饰的类,如OrderCreated。每个属性,要么是一个主键值,要么是一个值。如OrderCreated有一个orderId 属性。一个领域事件通常有元数据,如 事件ID,时间戳。当然这些元数据也可以被封装在事件的父类中。如OrderCreated就是一个空对象。
interface DomainEvent {}
interface OrderDomainEvent extends DomainEvent {}
class OrderCreated implements OrderDomainEvent {}
class DomainEventEnvelope<T extends DomainEvent> {
private String aggregateType;//事件元数据
private Object aggregateId;//事件元数据
private T event;
//...
}
扩充事件信息
一个事件也可以携带消费者需要的信息,如orderCreated携带商品列表,支付信息等,这样简化了事件消费,避免了其他服务从订单服务中重新 拉取信息,减少了服务请求的负载。
但是这样做的缺点就是,让事件类不稳定,事件类随着消费者需要的信息变化而不断变动。这会降低可维护性,因为这类改变会影响应用的多个 部分。所以满足每一个消费者需要是徒劳的。
但是通常情况下,包含在事件类中的信息是明确的。
定义领域事件
有多种策略定义领域事件,通常是当一个通知发生时,类似于“当X发生时,做Y”。如当“订单产生时,发送一份邮件给消费者”。
另一种策略越来越流行,“事件风暴”。事件风暴是用于理解复杂事物的一种以事件为中心的处理方式。事件风暴的结果是由聚合和事件组成 的以事件为中心的领域模型。
事件风暴由下列三部分组成:
- 头脑风暴事件——让专家集体讨论领域事件。领域事件用橙色的便贴纸陈列在一个粗略的时间线上。
- 定义事件的触发——让专家定义每个事件的触发,有下面几种情况:
- 用户动作,用蓝色便贴纸表示这个命令。
- 外部系统,用紫色便贴纸代表。
- 另一个领域事件。
- 通过时间。
- 定义聚合——让专家定义消费每个命令和产生对应事件的聚合。聚合通过黄色便贴纸记录。

事件风暴是快速创建一个领域模型的非常有用的技巧。
领域事件的产生和发布
领域事件可以由聚合发布,一个聚合也可以直接调用消息中间件API,缺点是聚合不能使用依赖注入,消息API需要作为方法参数传递,这样会将 基础框架和业务逻辑搅合在一起,是十分不可取的。
更好的方法是将聚合和调用消息Api的service分离。这样service可以使用依赖注入获取消息API的引用。聚合产生事件,将他们返回给service。 将事件返回给服务有多种方式,一种方式是在聚合的一个方法的返回值中防止事件列表,如Ticket聚合返回给service的事件如下:
public class Ticket {
public List<DomainEvent> accept(ZonedDateTime readyBy) {
this.acceptTime = ZonedDateTime.now();
this.readyBy = readyBy;
return singletonList(new TicketAcceptedEvent(readyBy));
}
}
service再调用聚合根的方法,并发布事件。如KitchenService调用Ticket如下。
public class KitchenService {
@Autowired
private TicketRepository ticketRepository;
@Autowired
private DomainEventPublisher domainEventPublisher;
public void accept(long ticketId, ZonedDateTime readyBy) {
Ticket ticket = ticketRepository.findById(ticketId).orElseThrow(() ->new TicketNotFoundException(ticketId));
List<DomainEvent> events = ticket.accept(readyBy);
domainEventPublisher.publish(Ticket.class, orderId, events);
}
}
另一种方法是聚合根对象在一个字段中存放事件,然后服务获取事件并发布,如下:
public class Ticket extends AbstractAggregateRoot {
public void accept(ZonedDateTime readyBy) {
this.acceptTime = ZonedDateTime.now();
this.readyBy = readyBy;
registerDomainEvent(new TicketAcceptedEvent(readyBy));
}
}
Ticket对象继承聚合根对象AbstractAggregateRoot,AbstractAggregateRoot定义了一个registerDomainEvent方法注册事件。服务将调用 AbstractAggregateRoot.getDomainEvents()获取事件。
推荐使用第一种方式,第二种方式虽然减少了代码重复,但是必须要继承自一个如AbstractAggregateRoot的超类,会阻止继承其他类。 另一个缺点是领域中的其他非根对象类想要发布事件,必须将事件先传递给聚合根。
- 可靠地发布领域事件 一个服务必须使用事务型消息来确保更新数据库中的聚合的同时发布事件。如OUTBOX,在事务提交后,也会想OUTBOX表中插入一条数据,然后 向消息中间件发布事件。
领域事件的发布可以让service实现一个接口来完成,类似如下:
public interface DomainEventPublisher {
void publish(String aggregateType, Object aggregateId, List<DomainEvent> domainEvents);
//...
}
但是这是一个通用的事件发布接口,不能确保一个服务职能发布对应的事件,如TicketDomainEvent是Ticket聚合的时间,KitchenService应该 发布只发布TicketDomainEvent的实现事件。一种更好的做法是将服务实现为AbstractAggregateDomainEventPublisher的子类。它提供了 用于发布领域事件的类型安全的接口。拥有两个泛型参数,A,表示聚合类型,E领域事件的标记接口类型。其代码如下:
public abstract class AbstractAggregateDomainEventPublisher<A, E extends DomainEvent> {
private Function<A, Object> idSupplier;
private DomainEventPublisher eventPublisher;
private Class<A> aggregateType;
protected AbstractAggregateDomainEventPublisher( DomainEventPublisher eventPublisher, Class<A> aggregateType,
Function<A, Object> idSupplier) {
this.eventPublisher = eventPublisher;
this.aggregateType = aggregateType;
this.idSupplier = idSupplier;
}
public void publish(A aggregate, List<E> events) {
eventPublisher.publish(aggregateType, idSupplier.apply(aggregate), (List<DomainEvent>) events);
}
}
那么Ticket聚合的时间发布如下:
public class TicketDomainEventPublisher extends AbstractAggregateDomainEventPublisher<Ticket, TicketDomainEvent> {
public TicketDomainEventPublisher(DomainEventPublisher eventPublisher) {
super(eventPublisher, Ticket.class, Ticket::getId);
}
}
上面的类只能发布TicketDomainEvent的子类。
Kitchen服务业务逻辑
Kitchen服务负责让restaurant管理他们的订单,该服务中有两个最主要的聚合Restaurant和Ticket。Restaurant提供了菜单信息、修改订单、 负责厨房的订单、开放时间、 并验证订单。Ticket表示被restaurant准备,并被快递员接收的订单。
Kitchen服务有下面三个入口适配器:
- REST API——被用户接口调用,使用KitchenService创建和更新Ticket。
- KitchenServiceCommandHandler——用于被分布式事务(如sagas)调用的异步请求/响应API,使用KitchenService创建和更新Ticket。
- KitchenServiceEventConsumer——订阅由Restaurant服务发布的领域事件。调用KitchenService创建和更新Restaurant。
拥有两个出口适配器: DB Adapter——实现TicketRepository和RestaurantRepository接口并且访问数据库。 DomainEventPublishingAdapter——实现DomainEventPublisher接口,并发布Ticket领域事件。
其业务逻辑如下图:

Ticket聚合
Ticket是Kitchen聚合的根对象,根据边界上下文的概念,Ticket是表示餐馆厨房的一个订单视图。不包含关于consumer的任何信息。主要目的是让厨房生产并拣货。甚至, KitchenService不会为这个聚合生成业务的唯一标识,它使用OrderService提供的ID。
Ticket有restaurantId、预计准备时间、准备项目集合、准备完成时间等字段。行为有接单、创建、准备(准备后订单确定,不能取消等)、 等待派送等。
Order服务业务逻辑
Order服务提供了创建、更新、取消订单的API,主要被Consumer调用。Order聚合是Order服务的根聚合,Restaurant聚合是Restaurant服务 的数据的部分复制,让Order服务有了给Order定价的能力。其设计如下:

入口适配器如下:
- REST API——被用户接口调用,使用OrderService创建和更新Orders。
- OrderEventConsumer——订阅Restaurant服务事件,创建和更新Restaurant的数据副本。
- OrderCommandHandlers——被分布式事务(如sagas)调用的异步请求/响应API。
- SagaReplyAdapter——订阅分布式事务(如sagas)返回通道。
出口适配器如下:
- DB Adapter——实现OrderRepository接口并且访问数据库。
- DomainEventPublishingAdapter——实现DomainEventPublisher接口,并发布Order领域事件。
- OutboundCommandMessageAdapter——实现CommandPublisher接口,发布命令消息给分布式事务(如sagas)的参与者。
Order聚合
order对象是Order聚合的根聚合。另外还有相关的OrderItem,DeliveryInfo,PaymentInfo等。
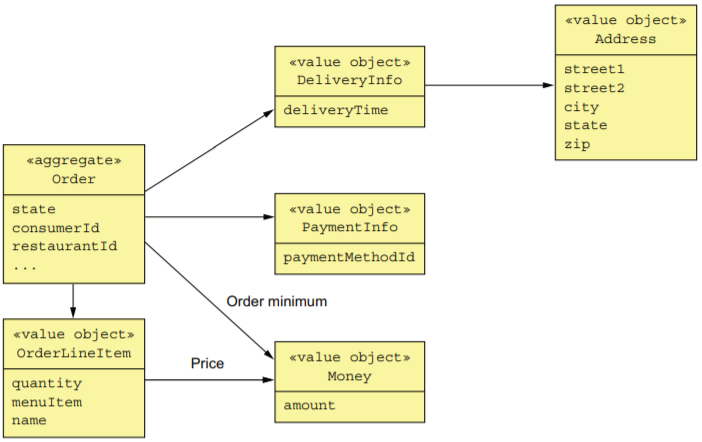
Order类的大致结构如下:
@Entity
@Table(name="orders")
@Access(AccessType.FIELD)
public class Order {
@Id
@GeneratedValue
private Long id;
@Version
private Long version;
private OrderState state;
private Long consumerId;
private Long restaurantId;
@Embedded
private OrderLineItems orderLineItems;
@Embedded
private DeliveryInformation deliveryInformation;
@Embedded
private PaymentInformation paymentInformation;
@Embedded
private Money orderMinimum;
}
其中version用于乐观锁,DeliveryInformation等通过@Embedded存储为Orders表的一列。
为了创建和更新Order,必须使用sagas和其他的服务协作交互。saga的第一步,验证操作可执行,并将订单状态改为pedding状态。pedding 状态是语法锁的一种措施,确保了分布式事务的隔离性。在创建一个APPROVAL_PEDDING状态的订单后,再调用sagas的各个参与者,最后将 状态改为APPROVED或者REJECTED。
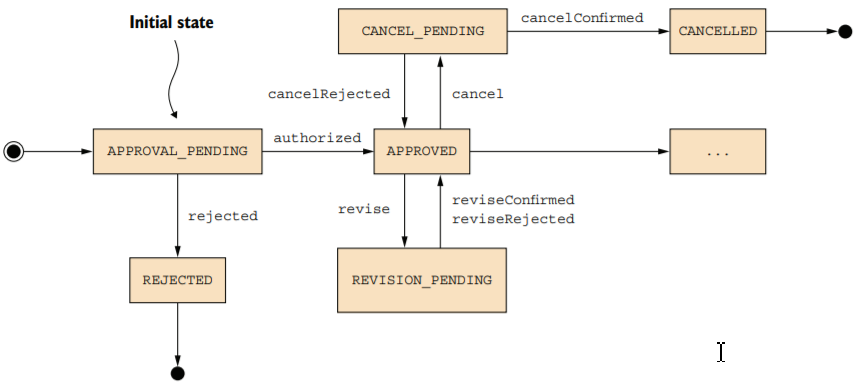
由于创建订单或者修改订单需要跨服务保持数据的一致性,所以,订单服务使用sagas,比kitchen等不需要分布式事务的服务复杂许多。