ConcurrentHashMap概述
讲述ConcurrentHashMap的原理及基本概念,对理解源码有很大帮助。
原理概览
在ConcurrentHashMap中通过一个Node<K,V>[]数组来保存添加到map中的键值对,而在同一个数组位置是通过链表和红黑树的形式来保存的。但是这个数组只有 在第一次添加元素的时候才会初始化,否则只是初始化一个ConcurrentHashMap对象的话,只是设定了一个sizeCtl变量,这个变量用来判断对象的一些状态和是 否需要扩容,后面会详细解释。
第一次添加元素的时候,默认初期长度为16,当往map中继续添加元素的时候,通过hash值跟数组长度取与来决定放在数组的哪个位置,如果出现放在同一个位置的 时候,优先以链表的形式存放,在同一个位置的个数又达到了8个以上,如果数组的长度还小于64的时候,则会扩容数组。如果数组的长度大于等于64了的话,在会将 该节点的链表转换成树。
通过扩容数组的方式来把这些节点给分散开。然后将这些元素复制到扩容后的新的数组中,同一个链表中的元素通过hash值的数组长度位来区分,是还是放在原来的 位置还是放到扩容的长度的相同位置去 。在扩容完成之后,如果某个节点的是树,同时现在该节点的个数又小于等于6个了,则会将该树转为链表。
取元素的时候,相对来说比较简单,通过计算hash来确定该元素在数组的哪个位置,然后在通过遍历链表或树来判断key和key的hash,取出value值。 往ConcurrentHashMap中添加元素的时候,里面的数据以数组的形式存放的样子大概是这样的:
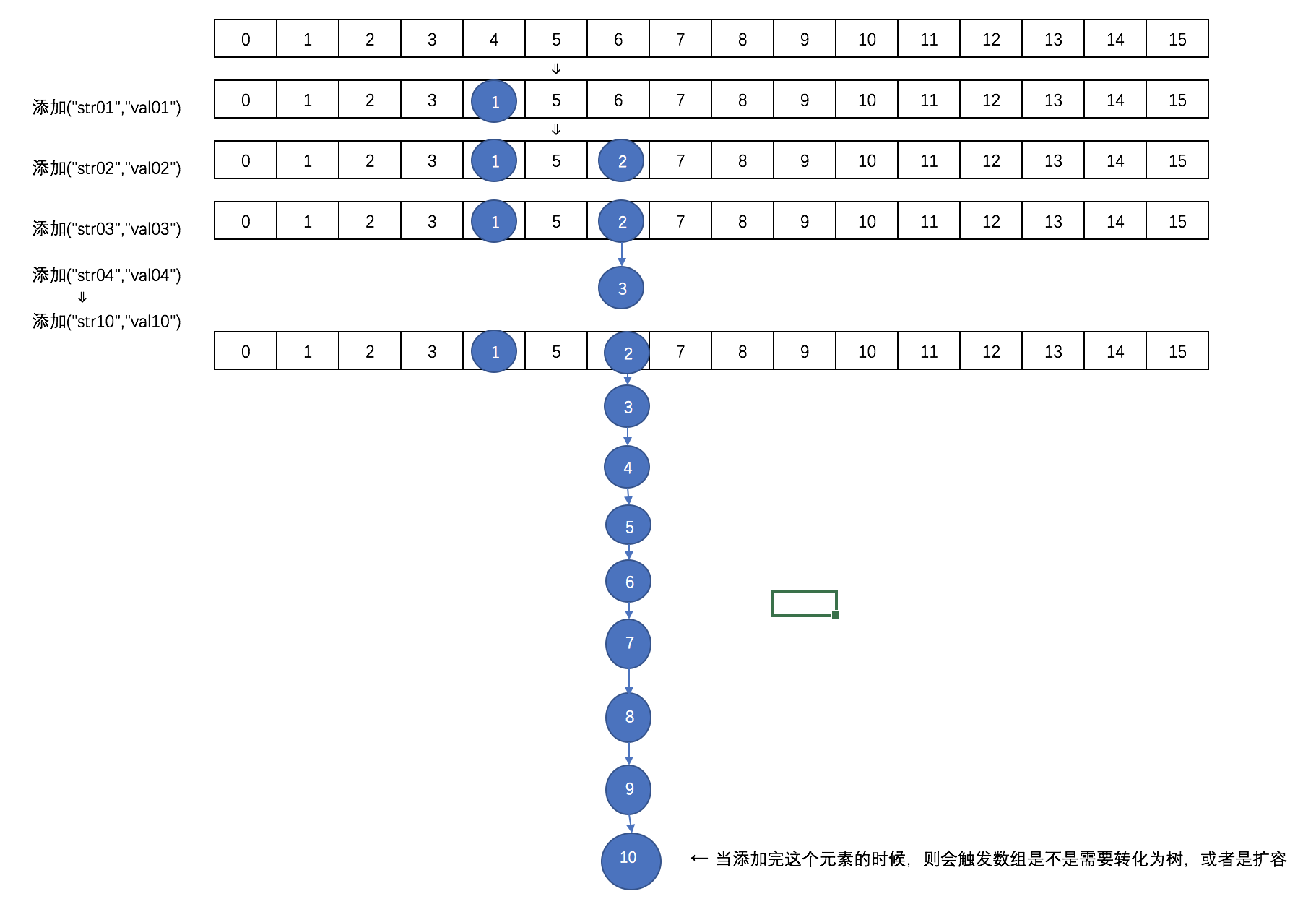
这个时候因为数组的长度才为16,则不会转化为树,而是会进行扩容。扩容后数组大概是这样的:
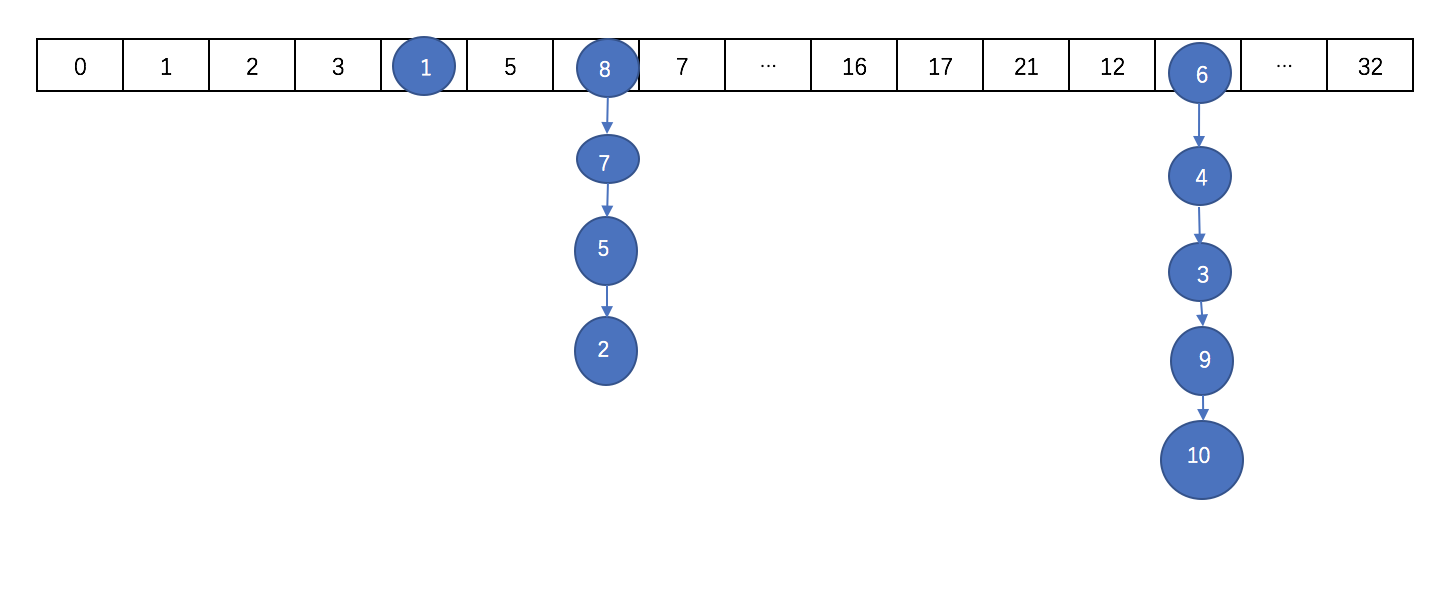
需要注意的是,扩容之后的长度不是32,扩容后的长度在后面细说。
如果数组扩张后长度达到64了,且继续在某个节点的后面添加元素达到8个以上的时候,则会出现转化为红黑树的情况。转化之后大概是这样:
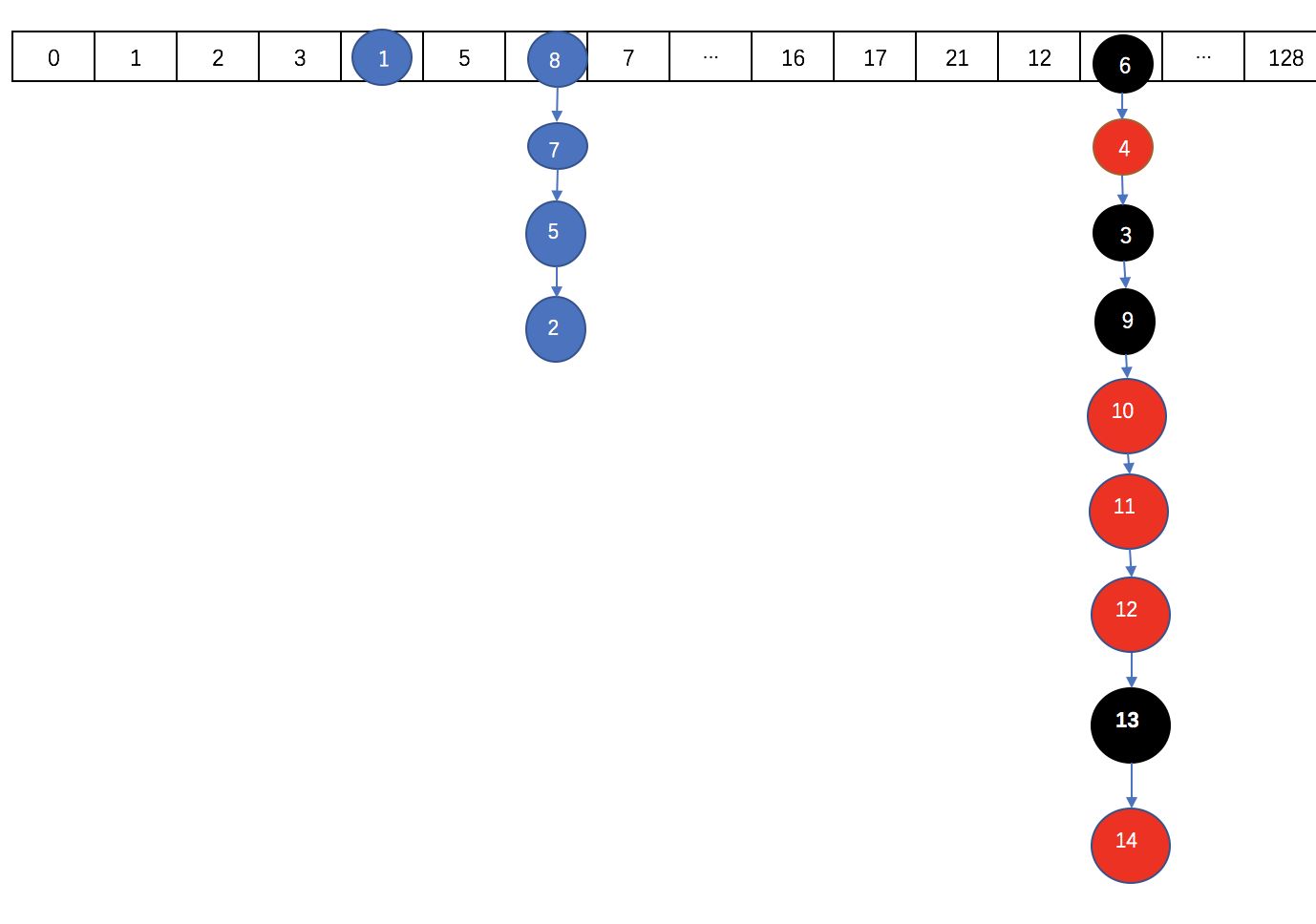
同步机制
在get操作中,根本没有使用同步机制,也没有使用unsafe方法,所以读操作是支持并发操作的。
那么写操作呢? 分析这个之前,先看看什么情况下会引起数组的扩容,扩容是通过transfer方法来进行的。而调用transfer方法的只有trePresize、 helpTransfer和addCount三个方法。
这三个方法又是分别在什么情况下进行调用的呢?
- tryPresize是在treeIfybin和putAll方法中调用,treeIfybin主要是在put添加元素完之后,判断该数组节点相关元素是不是已经超过8个的时候,如果超过 则会调用这个方法来扩容数组或者把链表转为树。
- helpTransfer是在当一个线程要对table中元素进行操作的时候,如果检测到节点的HASH值为MOVED的时候,就会调用helpTransfer方法,在helpTransfer 中再调用transfer方法来帮助完成数组的扩容
- addCount是在当对数组进行操作,使得数组中存储的元素个数发生了变化的时候会调用的方法。
所以引起数组扩容的情况如下:
- 只有在往map中添加元素的时候,在某一个节点的数目已经超过了8个,同时数组的长度又小于64的时候,才会触发数组的扩容。
- 当数组中元素达到了sizeCtl的数量的时候,则会调用transfer方法来进行扩容
那么在扩容的时候,可以不可以对数组进行读写操作呢?事实上是可以的。当在进行数组扩容的时候,如果当前节点还没有被处理(也就是说还没有设置为fwd节点), 那就可以进行设置操作。
如果该节点已经被处理了,则当前线程也会加入到扩容的操作中去。那么,多个线程又是如何同步处理的呢?
在ConcurrentHashMap中,同步处理主要是通过Synchronized和unsafe两种方式来完成的。
- 在取得sizeCtl、某个位置的Node的时候,使用的都是unsafe的方法,来达到并发安全的目的
- 当需要在某个位置设置节点的时候,则会通过Synchronized的同步机制来锁定该位置的节点。
- 在数组扩容的时候,则通过处理的步长和fwd节点来达到并发安全的目的,通过设置hash值为MOVED
- 当把某个位置的节点复制到扩张后的table的时候,也通过Synchronized的同步机制来保证现程安全